Perbedaann TOP DOWN AND BOTTOM UP
METODE PARSING (TOP DOWN AND BOTTOM UP)TEKNIK INFORMATIKA
Perbedaann TOP DOWN AND BOTTOM UP ?
1. top-down parsing?
Mengapa pada proses top down parsing, kita harus
menghilangkan recursive kiri, karena Compiler secara khusus menggunakan metode
top-down parsing. Karena itu, jika dalam sebuah grammar terdapat adanya
rekursif kiri, maka compiler akan melakukan infinite loop pada grammar
tersebut.
Left factoring diawali karena adanya sebuah masalah yang
dikenal dengan nama First/First Conflict. First/First Conflict adalah sebuah
kondisi dimana grammar tersebut memiliki 2 variabel yang sama yang menjadi
First dari sebuah variabel. Contoh :
S -> E | E T
Untuk menyelesaikan First/First Conflict tersebut
dilakukanlah proses left factoring sehingga dapat menjadi :
S -> E (epsilon | T)
S -> S'(epsilon | T)
dimana
S’ -> E
Perbedaan top down parsing dengan bottom up parsing
top down parsing adalah langkah dalam membentuk/membangun
sebuah parse tree berdasarkan input dimulai dari root dan membuat nodes untuk
parse tree secara preorder(depth first).
Bentuk umum dari top down parsing adalah recursive
descent parsing.
Sebuah recursive descent parsing adalah top down parsing
technique yang melaksanakan serangkaian prosedur rekursif untuk memproses
input, yang melibatkan backtracking (berarti pemindaian input berulang-ulang).
Backtracking memakan waktu dan karena itu, tidak efisien.
Itu sebabnya kasus khusus dari parsing top down dikembangkan, disebut
predictive parsing, di mana tidak ada backtracking diperlukan.
Sebuah dilema dapat terjadi jika ada left recursion
grammar. Bahkan dengan backtracking, Anda dapat menemukan parser untuk pergi ke
infinite loop.
contoh infinite loop pada top down parsing:
Sebuah konteks tata bahasa bebas dikatakan dibiarkan
rekursif jika memiliki derivasi dari bentuk A ⇒ ⋅ ⋅ ⋅ ⇒ Aα. Sebuah tata bahasa kiri-rekursif dapat menyebabkan
loop tak terbatas dalam parser top-down
S → Aa
A → Sb
→ b
S ⇒ Aa ⇒ ⇒ Sba Aaba ⇒ ⇒ Sbaba …
Ada algoritma untuk menghapus kiri rekursi dari konteks
tata bahasa bebas
bottom up parsing adalah sebuah langkah parsing
menggunakan langkah shift-reduce parsingShift reduce parsing bekerja
berdasarkan namanya, “Shift” dan “Reduce” sehingga setiap kali stack memegang
simbol-simbol yang tidak dapat dikurangi lagi, kita menggeser masukan lain, dan
ketika itu cocok, kita mengurangi.
contoh:
urutan yang di baca terlebih dahulu

Menurut kelompok kami bottom-up parsing lebih baik untuk
digunakan karena recursive-descent parsing mencoba untuk berhipotesis struktur
umum dari string input, yang berarti banyak trial-and-error terjadi sebelum
akhir string tercapai. Hal ini membuat mereka kurang efisien daripada bottom-up
parsing.
Selain itu Top-down parsing bisa lambat. Parser
recursive-keturunan mungkin memerlukan waktu eksponensial untuk menyelesaikan
pekerjaan mereka. Itu akan menempatkan keterbatasan parah pada skalabilitas
dari sebuah kompiler yang menggunakan parser top-down dan top down parsing
ketika di aplikasikan ke mesin, tidak akan bisa menyelesaikan sebagian besar
kasus-kasus umum, seperti left recursive karena akan terjadi looping terus
menerus.
Kelebihan top down parsing hanya lebih “intuitif,”
sehingga mereka lebih mudah untuk debug dan memelihara, dan lebih mudah
dipelajari dan ditulis ke dalam tools mesin. Namun secara performa dan
efisiensi bottom up parsing lebih baik dibandingkan dengan top down parsing.
2. Bottom up parsing
Bottom up merupakan salah satu metode yang digunakan untuk
melakukan parsing. Operasi yang terdapat pada bottom up parser adalah shift dan
reduce, sehingga seringkali bottom up parser disebut dengan shift-reduce
parser. Pada setiap tahapan reduksi, substring yang berada disisi kanan dari
sebuah production rule (RHS) digantikan dengan symbol dari pada LHS. Untuk
membuat sebuah parsing table maka dibutuhkan DFA dari grammar tersebut. Ada
beberapa jenis parsing table, antara lain LR(0), LR(1), dan SLR.
Bottom-up
Versus Top-down
The bottom-up name comes from the concept of a parse tree,
in which the most detailed parts are at the bottom of the (upside-down) tree,
and larger structures composed from them are in successively higher layers,
until at the top or "root" of the tree a single unit describes the
entire input stream. A bottom-up parse discovers and processes that tree
starting from the bottom left end, and incrementally works its way upwards and
rightwards.[1] A
parser may act on the structure hierarchy's low, mid, and highest levels
without ever creating an actual data tree; the tree is then merely implicit in
the parser's actions. Bottom-up parsing lazily waits until it has scanned and
parsed all parts of some construct before committing to what the combined
construct is.
 
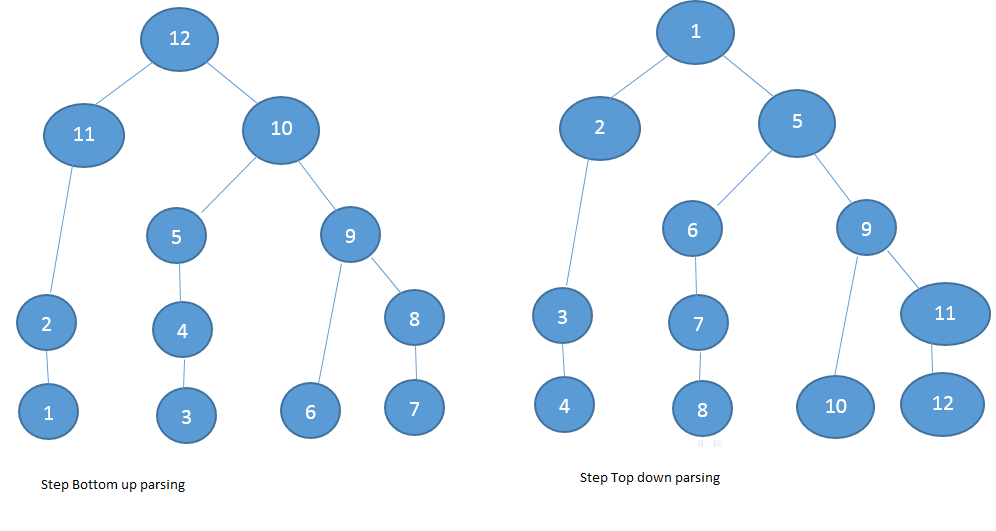
Typical parse tree for
A = B + C*2; D = 1 |
Bottom-up parse steps
|

Top-down parse steps
|

The opposite of this are top-down parsing methods, in which
the input's overall structure is decided (or guessed at) first, before dealing
with mid-level parts, leaving the lowest-level small details to last. A
top-down parser discovers and processes the hierarchical tree starting from the
top, and incrementally works its way downwards and rightwards. Top-down parsing
eagerly decides what a construct is much earlier, when it has only scanned the
leftmost symbol of that construct and has not yet parsed any of its parts. Left cornerparsing is
a hybrid method which works bottom-up along the left edges of each subtree, and
top-down on the rest of the parse tree.
If a language grammar has multiple rules that may
start with the same leftmost symbols but have different endings, then that
grammar can be efficiently handled by a deterministicbottom-up
parse but cannot be handled top-down without guesswork and backtracking.
So bottom-up parsers handle a somewhat larger range of computer language
grammars than do deterministic top-down parsers.
SUMBER :
http://cs.stackexchange.com/questions/9963/why-is-left-recursion-bad
http://en.wikipedia.org/wiki/LL_parser#FIRST.2FFIRST_Conflict
http://en.wikipedia.org/wiki/Left_recursion
Semoga Bermanfaat dengan ilmunya :)


{kind=link}
{kind=link}
Komentar
Posting Komentar